

1ĪóAI│╔Ž±╣żū„┴„į┌ßtīWė░Ž±ųąĄ─ā×ä▌
é„Įy│╔Ž±╣żū„┴„│╠Ż║ąž▓┐X╣Ō║═CTÅVĘ║ė├ė┌COVID-19 Ą─║Y▓ķ║═į\öÓĪŻį┌COVID-19┤¾┴„ąąŲ┌ķgŻ¼▓╔ė├ĘŪĮėė|╩ĮūįäėłDŽ±▓╔╝»╣żū„┴„│╠ęį▒▄├ŌĖą╚ŠĄ─ć└ųž’LļUĘŪ│Żųžę¬ĪŻ╚╗Č°Ż¼é„ĮyĄ─│╔Ž±╣żū„┴„│╠░³└©╝╝ąg╚╦åT║═╗╝š▀ų«ķg▓╗┐╔▒▄├ŌĄ─Įėė|ĪŻ╠žäeĄžŻ¼į┌╗╝š▀Č©╬╗ųąŻ¼╝╝ąg╚╦åTŽ╚Ė∙ō■ĮoČ©Ą─ĘĮ░ĖÄ═ų·╗╝š▀ö[ū╦ä▌Ż¼ļS║¾į┌ęĢėX╔ŽūRäe╗╝š▀╔Ē╔ŽĄ──┐ś╦╔Ē¾w▓┐╬╗╬╗ų├Ż¼▓ó╩ųäėš{š¹╗╝š▀║═X╔õŠĆ╣▄ų«ķgĄ─ŽÓī”╬╗ų├║═ū╦ä▌ĪŻ▀@ę╗▀^│╠╩╣╝╝ąg╚╦åT┼c╗╝š▀├▄ŪąĮėė|Ż¼ī¦ų┬▓ĪČŠ▒®┬ČĄ─G’LļUĪŻę“┤╦Ż¼ąĶę¬ĘŪĮėė|╩Į║═ūįäė╗»Ą─│╔Ž±╣żū„┴„│╠üĒąĪ╗»Įėė|ĪŻ
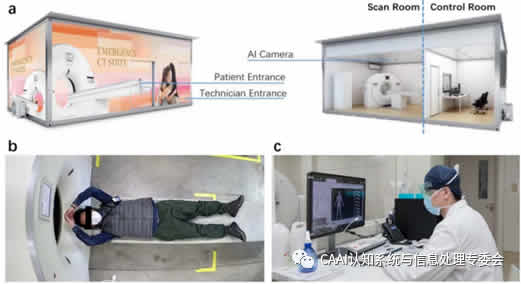
╚╦╣żųŪ─▄│╔Ž±╣żū„┴„│╠Ż║įSČÓ¼F┤·Ą─X╣Ō║═CTŽĄĮyČ╝┼õéõ┴╦ė├ė┌▓Ī╚╦▒OūoĄ─özŽ±ÖCĪŻį┌COVID-19▒¼░lŲ┌ķgŻ¼▀@ą®įOéõ┤┘▀M┴╦ĘŪĮėė|Æ▀├Ķ╣żū„┴„│╠Ą─īŹ╩®ĪŻ╝╝ąg╚╦åT┐╔ęį═©▀^özŽ±ÖCĄ─īŹĢręĢŅl┴„Å─┐žųŲ╩ę▒O┐ž▓Ī╚╦ĪŻį┌▀@ĘNŪķørŽ┬Ż¼╚╦╣żųŪ─▄─▄ē“═©▀^Å─ęĢėXé„ĖąŲ„½@╚ĪĄ─öĄō■ųąūRäe╗╝š▀Ą─ū╦ä▌║═ą╬ĀŅüĒūįäėł╠ąą▓┘ū„Ż¼ęį┤_Č©╝čÆ▀├ĶģóöĄĪŻ▀@śėĄ─ūįäė╗»╣żū„┴„│╠┐╔ęį’@ų°╠ßGÆ▀├Ķą¦┬╩▓ó£p╔┘▓╗▒žę¬Ą─▌Ś╔õ▒®┬ČĪŻę╗éĆ’@ų°Ą─└²ūė╩Ū╗∙ė┌ė╔┐╔ęĢ╚╦╣żųŪ─▄╝╝ągų¦│ųĄ─ęŲäėCTŲĮ┼_ūįäėÆ▀├Ķ╣żū„┴„Ż¼╚ńłD1(a)╦∙╩ŠĪŻęŲäėŲĮ┼_═Ļ╚½d┴óŻ¼Ä¦ėą╗∙ė┌╚╦╣żųŪ─▄Ą─ŅAÆ▀├Ķ║═į\öÓŽĄĮyĪŻ╦³▒╗ųžą┬įOėŗ│╔ę╗éĆ═Ļ╚½Ė¶ļxĄ─Æ▀├Ķ╩ę║═┐žųŲ╩ęŻ¼ęį▒▄├Ō╝╝ąg╚╦åT║═╗╝š▀ų«ķg▓╗▒žę¬Ą─╗źäėĪŻ▀M╚ļÆ▀├Ķ╩ę║¾Ż¼═©▀^ęĢėX║═┬ĀėX╠ß╩ŠŻ¼ųĖ╩Š╗╝š▀į┌▓Ī┤▓╔Žö[║├ū╦ä▌(łD1(b))ĪŻ╝╝ąg╚╦åT┐╔ęį═©▀^┤░æ¶ė^▓ņŻ¼ę▓┐╔ęį═©▀^Æ▀├Ķ╩ęā╚░▓čbį┌╠ņ╗©░Õ╔ŽĄ─╚╦╣żųŪ─▄özŽ±ÖCé„▌öĄ─īŹĢręĢŅlŻ¼▓óį┌▒žę¬ĢrąŻš²▓Ī╚╦Ą─ū╦ä▌(łD1(c))ĪŻ╗╝š▀Č©╬╗╦ŃĘ©īóÅ─ė├ššŽÓÖC[1]▓Č½@Ą─łDŽ±ųąūįäė╗ųÅ═╗╝š▀Ą─3Dū╦æB║══Ļ╚½ųžĮ©Ą─ŠWĖ±ĪŻ╗∙ė┌3DŠWĖ±Ż¼╗╝š▀─┐ś╦╔Ē¾w▓┐ĘųĄ─Æ▀├ĶĘČć·║═3Dųąą─ŠĆČ╝▒╗╣└ėŗ▓ó▐DōQ│╔┐žųŲą┼╠¢║═ā×╗»Ą─Æ▀├ĶģóöĄŻ¼ęį╣®╝╝ąg╚╦åT“×ūCĪŻę╗Ą®║╦īŹŻ¼▓Ī┤▓īóūįäėī”£╩ISOųąą─Ż¼▓óęŲ╚ļÆ▀├Ķ╝▄▀MąąÆ▀├ĶĪŻ▓╔╝»ĄĮCTłDŽ±║¾Ż¼īóī”Ųõ▀Mąą╠Ä└Ē║═Ęų╬÷Ż¼ęį▒Ń▀Mąą║Y▓ķ║═į\öÓĪŻ2ĪóAIłDŽ±į÷ÅŖį┌COVID-19ųąĄ─Š▀¾wæ¬ė├
AIłDŽ±╠Ä└Ēį┌COVID-19ų╬»¤ųąŠ▀¾wū„ė├į┌ė┌Ż║ßśī”╠ß╣®Ą─łDŽ±▓─┴ŽŻ©ą╬╩Į┐╔ęį╩ŪCTŻ¼X╣ŌŻ®Ż¼└¹ė├ÖCŲ„īW┴Ģ╦ŃĘ©ī”łDŽ±▀Mąą╠Ä└ĒŻ¼Įo│÷1.äØĘų│÷Ę╬▓┐ģ^ė“║═ōpé¹ģ^ė“Ż╗2.į\öÓ╩Ūʱ×ķą┬GĘ╬čū╗╝š▀Ż╗3.╠ß╣®ėąų·ė┌ßtūo╚╦åTū„ų╬»¤ĘĮ░ĖøQ▓▀Ą─┴┐╗»ģóöĄĪŻ
2.1 ģ^ė“äØĘų
┤╦Łh╣ØĄ─ū„ė├į┌ė┌Ż¼ī”ę╔╦Ų╗╝š▀Ę╬▓┐ģ^ė“┼─özČ°Ą├ĄĮĄ─łDŽ±▀MąąŅA╠Ä└ĒŻ¼ęį╠ß╣®║¾└m▓┘ū„ĪŻīŹ╩®īė├µŻ¼┤╦Łh╣Ø░³║¼ā╔▓┐Ęų╣żū„Ż║Ę╬▓┐ģ^ė“äØĘų║═ōpé¹ģ^ė“ĪŻ▒Ē1╩Ūę╗ą®łDŽ±äØĘųį┌COVID-19æ¬ė├ųąĄ─蹊┐ģR┐éĪŻ
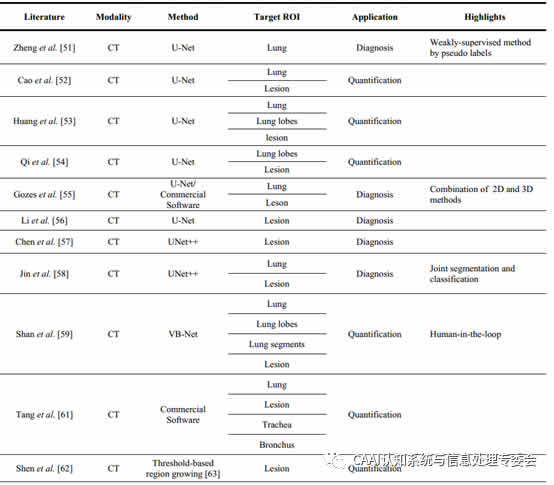
▒Ē1 łDŽ±äØĘųį┌COVID-19ųąĄ─æ¬ė├
ęįĘ╬ģ^ė“×ķī¦Ž“Ą─ĘĮĘ©ų╝į┌īóĘ╬ģ^ė“Ż¼╝┤š¹éĆĘ╬║═Ę╬╚~Ż¼┼cCT╗“X╔õŠĆųąĄ─Ųõ╦¹Ż©▒│Š░Ż®ģ^ė“Ęųķ_Ż¼▀@▒╗šJ×ķ╩Ūę╗éĆ▒žę¬Ą─▓Į¾EŻ¼į┌COVID-19Ą─║Y▓ķųą[3-10]ĪŻ└²╚ńŻ¼JinĄ╚╚╦[2]╠ß│÷┴╦ę╗ĘNė├ė┌CTłDŽ±ųąCOVID-19║Y▓ķĄ─ā╔J╣▄Ą└Ż¼Ųõųąš¹éĆĘ╬ģ^ė“Ž╚ė╔ę╗éĆ╗∙ė┌UNet++Ą─ĘųĖŅŠWĮjėąą¦ĘųĖŅ│÷üĒĪŻ
ęį├µŽ“Ę╬ōpé¹Ą─ĘĮĘ©ų╝į┌īóĘ╬ųąĄ─▓ĪūāŻ©╗“Įī┘║═▀\äėé╬ė░Ż®Å─Ę╬ģ^Ęųļx│÷üĒĪŻę“×ķ▓Īūā╗“ĮY╣Ø┐╔─▄║▄ąĪŻ¼ėąČÓĘNą╬ĀŅ║═╝y└ĒŻ¼Č©╬╗▓Īūā╗“ĮY╣ØĄ─ģ^ė“╩Ū▒žąĶĄ─Ż¼═©│Ż▒╗šJ×ķ╩Ūę╗ĒŚŠ▀ėą╠¶æąįĄ─Öz£y╚╬äšĪŻųĄĄ├ūóęŌĄ─╩ŪŻ¼│²┴╦ĘųĖŅ═ŌŻ¼į┌║Y▀xųąŻ¼ūóęŌÖCųŲę▓▒╗šJ×ķ╩Ūėąą¦Ą─Č©╬╗ĘĮĘ©ĪŻ
2.2 COVID-19Ą─į\öÓ
ī”COVID-19Ą─į\öÓ▒Š┘|╔Ž╩Ūę╗éĆĘųŅÉå¢Ņ}Ż¼═©│ŻĄ─ĘųŅÉĮY╣¹ėą╚²Ż║ĘŪĘ╬čūŻ¼ĘŪą┬GĘ╬čū║═ą┬GĘ╬čūĪŻ▒Ē2╩Ūę╗ą®COVID-19Ą─ĘųŅÉ蹊┐ĪŻ
╝{┴ųĄ╚╚╦[11]╠ß│÷┴╦╚²ĘN▓╗═¼Ą─╔ŅČ╚īW┴Ģ─Żą═Ż¼╝┤ResNet50ĪóInceptionV3║═Inception-ResNetV2Ż¼ęįÖz£yX╔õŠĆłDŽ±ųąĄ─COVID-19Ėą╚ŠŪķørĪŻųĄĄ├ūóęŌĄ─╩ŪŻ¼į┌▒ŠčąŠ┐ųąŻ¼ID-19öĄō■╝»[12]║═KaggleĄ─ąž▓┐X╔õŠĆłDŽ±Ż©Ę╬čūŻ®ę▓▒╗ė├üĒą╬│╔öĄō■╝»ĪŻ50└²COVID-19╗╝š▀Ą─ąž▓┐XŠĆłDŽ±║═50└²š²│Żąž▓┐XŠĆłDŽ±ĪŻįuārĮY╣¹▒Ē├„Ż¼ResNet50─Żą═Š▀ėąGĄ─ĘųŅÉąį─▄Ż¼£╩┤_┬╩×ķ98.0%Ż¼Č°InceptionV3Ą─£╩┤_┬╩×ķ97.0%Ż¼Inception-ResNetV2Ą─£╩┤_┬╩×ķ87%ĪŻ
2.3 ┴┐╗»ģóöĄ
ė╔ė┌─┐Ū░Ą─┤¾▓┐Ęų╣żū„╝»ųąį┌COVID-19Ą─ŅAį\öÓ╔ŽŻ¼╬ęéāūóęŌĄĮ蹊┐COVID-19Ą─║¾└m╣żū„╚į╚╗ĘŪ│ŻėąŽ▐ĪŻų╗ėą║▄╔┘Ą─ćLįćŻ¼ō■╬ęéā╦∙ų¬ĪŻ└²╚ńŻ¼╔Ž║Ż┬ō║Ž│╔Ž±ųŪ─▄(UII)Ą─蹊┐╚╦åTįćłD╩╣ė├╗∙ė┌ÖCŲ„īW┴ĢĄ─ĘĮĘ©║═┐╔ęĢ╗»╝╝ągüĒč▌╩Šūā╗»╗╝š▀Ėą╚Šģ^ė“Ą─¾wĘe┤¾ąĪĪó├▄Č╚Ą╚┼R┤▓ŽÓĻPę“╦žĪŻų«║¾Ż¼īóūįäė╔·│╔┼R┤▓ł¾ĖµŻ¼ęįīó▀@ą®ūā╗»ū„×ķöĄō■Ę┤ė││÷üĒė╔┼R┤▓īŻ╝ę“īäėĄ─ųĖī¦Ż¼ęį┤_Č©ęįŽ┬│╠ą“Ż¼ęŖłD2ĪŻ
3Īóå¢Ņ}║═š╣═¹
öĄō■╩š╝»╩ŪCOVID-19æ¬ė├│╠ą“ķ_░lÖCŲ„īW┴ĢĘĮĘ©Ą─▓ĮĪŻ▒M╣▄ėą┤¾┴┐Ą─╣½╣▓CT╗“X╔õŠĆöĄō■╝»ė├ė┌Ę╬▓┐╝▓▓ĪŻ¼Ą½X╔õŠĆ║═CTÆ▀├Ķī”COVID-19Ą─æ¬ė├─┐Ū░Č╝▀Ć▓╗ÅVĘ║Ż¼▀@ūĶĄK┴╦╚╦╣żųŪ─▄ĘĮĘ©Ą─蹊┐║═░lš╣ĪŻCohenĄ╚╚╦Å─ŠWšŠ║═│÷░µ╬’╩š╝»ßtīWłDŽ±üĒäōĮ©COVID-19łDŽ±öĄō■╩š╝»Ż¼╦³─┐Ū░░³║¼123éĆš²├µęĢłDX╔õŠĆĪŻCOVID-CTöĄō■╝»╩ŪÅ─700ČÓĘ▌ĻPė┌COVID-19Ą─medRxiv║═bioRxivĄ─ŅAėĪ╬─½Iųą╩š╝»üĒĄ─Ż¼░³└©288Åł┤_į\COVID-19╗╝š▀Ą─CTŪąŲ¼║═10└²┤_į\COVID-19▓Ī└²Ą─╚²ŠSCTłDŽ±ĪŻ┤╦═ŌŻ¼COVID-19CTĘųĖŅöĄō■╝»▀Ć░³║¼üĒūį60└²╗╝š▀Ą─100éĆ▌SŽ“CTŪąŲ¼Ż¼ęįJPGłDŽ±Ą─ĘĮ╩Įš╣╩ŠĪŻ┐╔ęŖ─┐Ū░Ž▐ųŲAIė┌COVID-19╔Žæ¬ė├Ą─ų„ę¬å¢Ņ}╩Ū╚▒Ę”┤¾┴┐Īó═Ļš¹Īó┐╔┐┐Ą─öĄō■╝»ĪŻ
š╣═¹╬┤üĒŻ¼ŅAėŗīóėąĖ³ČÓĄ─╚╦╣żųŪ─▄æ¬ė├│╠ą“▒╗╝{╚ļłDŽ±▓╔╝»╣żū„┴„│╠Ż¼ęį╠ßGÆ▀├Ķ┘|┴┐Īó£p╔┘▓Ī╚╦Ą─▒╗▌Ś╔õ┴┐ĪŻ└²╚ńŻ¼ąĶę¬Ė³£╩┤_Ą─╗∙ė┌╚╦╣żųŪ─▄Ą─ūįäė╗»ISOųąą─║═Æ▀├ĶĘČć·┤_Č©Ż¼ęį┤_▒Ż╝čĄ─łDŽ±┘|┴┐ĪŻ┤╦═ŌŻ¼X╔õŠĆŲž╣ŌģóöĄ┐╔ęį═©▀^╚╦╣żųŪ─▄üĒ═ŲöÓ╗╝š▀Ą─╔Ē¾wģ^ė“║±Č╚Ż¼ūįäėėŗ╦Ń║═ā×╗»Ą─Ż¼┤_▒Żį┌Æ▀├Ķ▀^│╠ųą╩╣ė├š²┤_Ą─▌Ś╔õ┴┐Ż¼▀@ī”ė┌Ą═ä®┴┐│╔Ž±╠žäeųžę¬ĪŻ
 |
| ╔╠ė├ÖCŲ„╚╦ Disinfection Robot š╣ÅdÖCŲ„╚╦ ųŪ─▄└¼╗°šŠ ▌å╩ĮÖCŲ„╚╦Ąū▒P ėŁ┘eÖCŲ„╚╦ ęŲäėÖCŲ„╚╦Ąū▒P ųvĮŌÖCŲ„╚╦ ūŽ═ŌŠĆŽ¹ČŠÖCŲ„╚╦ ┤¾Ų┴ÖCŲ„╚╦ ņF╗»Ž¹ČŠÖCŲ„╚╦ Ę■äšÖCŲ„╚╦Ąū▒P ųŪ─▄╦═▓═ÖCŲ„╚╦ ņF╗»Ž¹ČŠÖC ÖCŲ„╚╦OEM┤·╣żÅS Ž¹ČŠÖCŲ„╚╦┼┼├¹ ųŪ─▄┼õ╦═ÖCŲ„╚╦ łDĢ°^ÖCŲ„╚╦ ī¦ę²ÖCŲ„╚╦ ęŲäėŽ¹ČŠÖCŲ„╚╦ ī¦į\ÖCŲ„╚╦ ėŁ┘eĮė┤²ÖCŲ„╚╦ Ū░┼_ÖCŲ„╚╦ ī¦ė[ÖCŲ„╚╦ ŠŲĄĻ╦═╬’ÖCŲ„╚╦ įŲ█E┐Ų╝╝ØÖÖCŲ„╚╦ įŲ█EŠŲĄĻÖCŲ„╚╦ ųŪ─▄ī¦į\ÖCŲ„╚╦ |



